9-10
1.2021年11月每天新用户的次日留存率
用户行为日志表tb_user_log
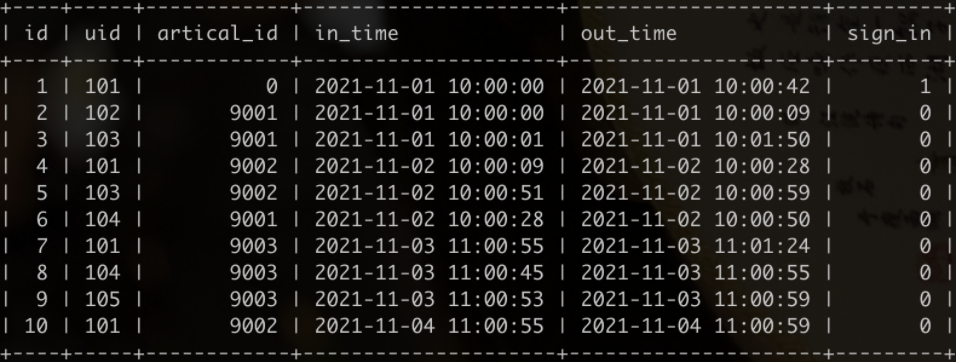
(uid-用户ID, artical_id-文章ID, in_time-进入时间, out_time-离开时间, sign_in-是否签到)
问题:统计2021年11月每天新用户的次日留存率(保留2位小数)
注:
次日留存率为当天新增的用户数中第二天又活跃了的用户数占比。
如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过,结果按日期升序。
输出示例:
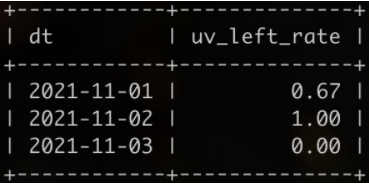
示例数据的输出结果如下
解释:
11.01有3个用户活跃101、102、103,均为新用户,在11.02只有101、103两个又活跃了,因此11.01的次日留存率为0.67;
11.02有104一位新用户,在11.03又活跃了,因此11.02的次日留存率为1.00;
11.03有105一位新用户,在11.04未活跃,因此11.03的次日留存率为0.00;
11.04没有新用户,不输出。
AC:
select t1.dt,round(count(t2.uid)/count(t1.uid),2) uv_left_rate
from (select uid
,min(date(in_time)) dt
from tb_user_log
group by uid) as t1 -- 每天新用户表
left join (select uid , date(in_time) dt
from tb_user_log
union
select uid , date(out_time)
from tb_user_log) as t2 -- 用户活跃表
on t1.uid=t2.uid
and t1.dt=date_sub(t2.dt,INTERVAL 1 day)
where date_format(t1.dt,'%Y-%m') = '2021-11'
group by t1.dt
order by t1.dt2.牛客每个人最近的登录日期(四)
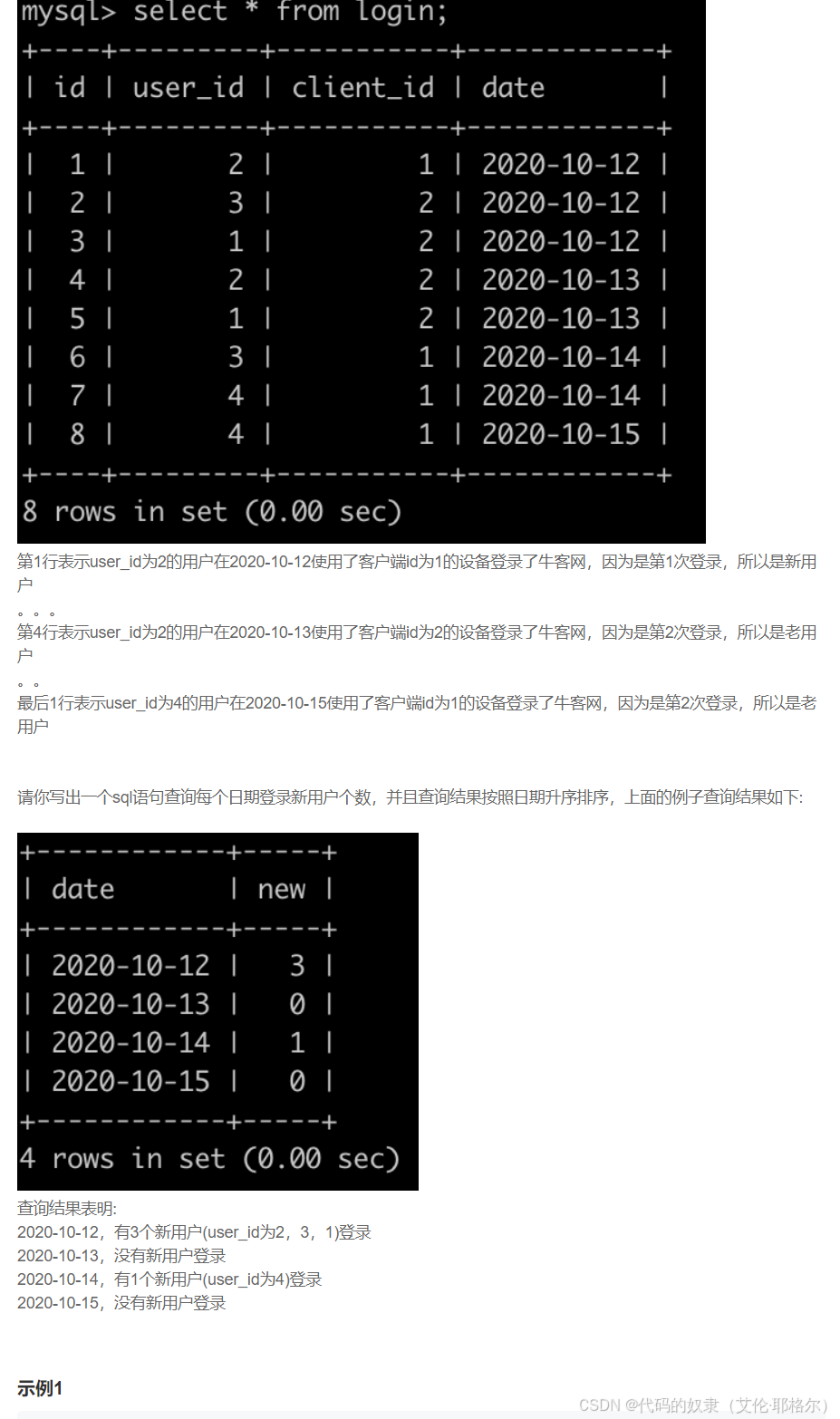
输出样例:
请在这里给出输出样例。例如:
2020-10-12|3
2020-10-13|0
2020-10-14|1
2020-10-15|0
AC:
SELECT
a.date
,COUNT(b.user_id) AS new
FROM (
SELECT
DISTINCT date
FROM login ) AS a
LEFT JOIN (
SELECT
MIN(date) AS min_date
,user_id
FROM login
GROUP BY user_id
) AS b ON a.date = b.min_date
GROUP BY a.date
ORDER BY a.date
3.每篇文章同一时刻最大在看人数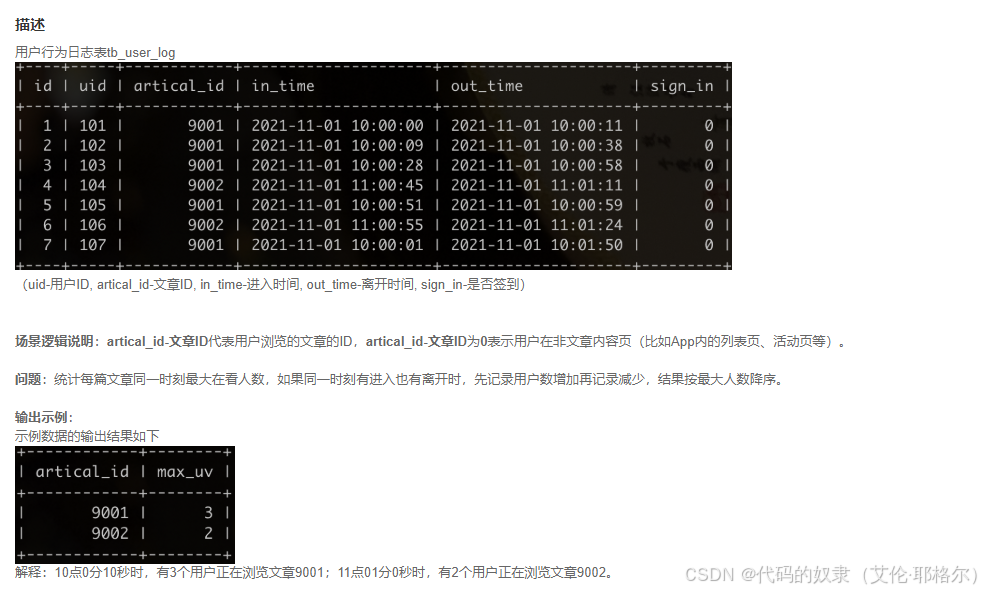
AC:
select artical_id,max(cnt) as max_uv
from (
select t2.uid,t2.artical_id,count(distinct t1.uid) cnt
from tb_user_log t1,tb_user_log t2
where t1.artical_id = t2.artical_id
and t1.in_time <=t2.out_time
and t1.out_time >= t2.out_time
and t1.artical_id <> 0
group by t2.uid,t2.artical_id
)c
group by artical_id
order by max_uv desc
4.最近的三笔订单
表:Customers

customer_id 是该表具有唯一值的列
该表包含消费者的信息
表:Orders
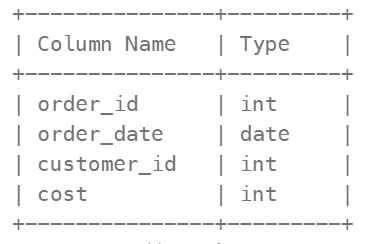
order_id 是该表具有唯一值的列
该表包含 id 为 customer_id 的消费者的订单信息
每一个消费者 每天一笔订单
写一个解决方案,找到每个用户的最近三笔订单。如果用户的订单少于 3 笔,则返回他的全部订单。
返回的结果按照 customer_name 升序 排列。如果有相同的排名,则按照 customer_id 升序 排列。如果排名还有相同,则按照 order_date 降序 排列。
输入:
Customers

Orders

AC:
select c.name customer_name,o.*
from Customers c inner join (
select o1.customer_id,o1.order_id,order_date
from Orders o1
where (
select count(distinct o2.order_date)
from Orders o2
where o2.customer_id=o1.customer_id
and o2.order_date>o1.order_date
)<3
order by customer_id,order_date desc
)o on c.customer_id=o.customer_id
order by 1,2,4 desc5.指定日期的产品价格
产品数据表: Products
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| new_price | int |
| change_date | date |
+---------------+---------+
(product_id, change_date) 是此表的主键(具有唯一值的列组合)。
这张表的每一行分别记录了 某产品 在某个日期 更改后 的新价格。编写一个解决方案,找出在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10 。
以 任意顺序 返回结果表。
结果格式如下例所示。
示例 1:
输入:
Products 表:
+------------+-----------+-------------+
| product_id | new_price | change_date |
+------------+-----------+-------------+
| 1 | 20 | 2019-08-14 |
| 2 | 50 | 2019-08-14 |
| 1 | 30 | 2019-08-15 |
| 1 | 35 | 2019-08-16 |
| 2 | 65 | 2019-08-17 |
| 3 | 20 | 2019-08-18 |
+------------+-----------+-------------+
输出:
+------------+-------+
| product_id | price |
+------------+-------+
| 2 | 50 |
| 1 | 35 |
| 3 | 10 |
+------------+-------+AC:
select p1.product_id, ifnull(p2.new_price, 10) as price
from (
select distinct product_id
from products
) as p1 -- 所有的产品
left join (
select product_id, new_price
from products
where (product_id, change_date) in ( -- 2019-08-16之前价格的最大值
select product_id, max(change_date)
from products
where change_date <= '2019-08-16'
group by product_id
)
) as p2 -- 在 2019-08-16 之前有过修改的产品和最新的价格
on p1.product_id = p2.product_id6.向公司 CEO 汇报工作的所有人
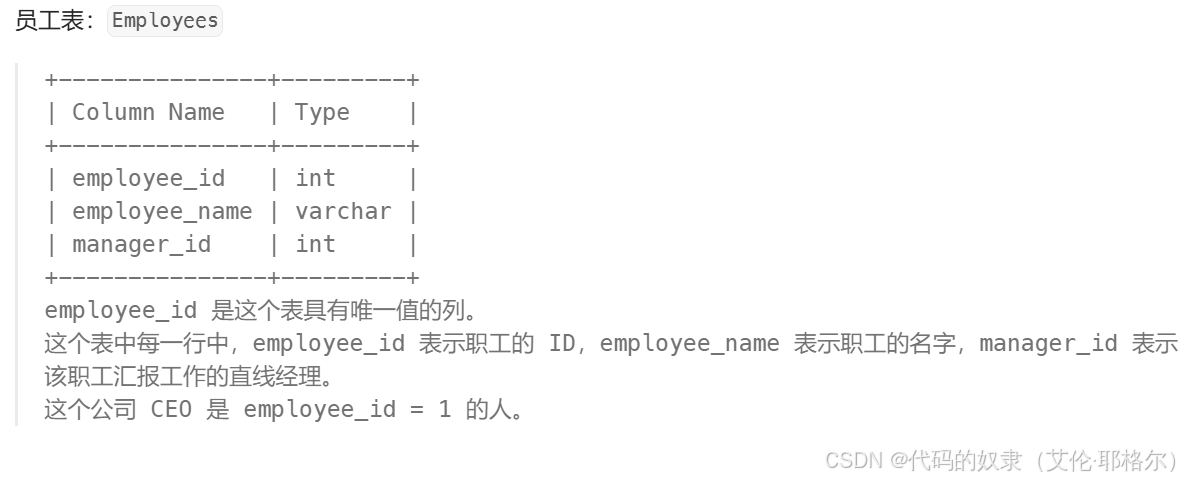
编写解决方案,找出所有直接或间接向公司 CEO 汇报工作的职工的 employee_id 。
由于公司规模较小,经理之间的间接关系 不超过 3 个经理 。
可以以 任何顺序 返回无重复项的结果。
返回结果示例如下。

AC:
select a.employee_id
from Employees a
join Employees b on a.manager_id = b.employee_id
join Employees c on b.manager_id = c.employee_id
where a.employee_id != 1
and c.manager_id = 1;
7.购买了产品A和产品B却没有购买产品C的顾客


AC:
select c.customer_id,c.customer_name
from Customers c left
join Orders o on c.customer_id = o.customer_id
group by c.customer_id ,c.customer_name
having sum(if(o.product_name = 'A',1,0)) > 0 a
nd sum(if(o.product_name = 'B',1,0)) > 0
and sum(if(o.product_name = 'C',1,0)) = 08.找到连续区间的开始和结束数字



AC:
select a.log_id as start_id ,min(b.log_id) as end_id from
(select log_id from Logs where log_id-1 not in (select * from Logs)) a,
(select log_id from Logs where log_id+1 not in (select * from Logs)) b
where b.log_id>=a.log_id
group by a.log_id9.查找成绩处于中游的学生

成绩处于中游的学生是指至少参加了一次测验, 且得分既不是最高分也不是最低分的学生。
编写解决方案,找出在 所有 测验中都处于中游的学生 (student_id, student_name)。不要返回从来没有参加过测验的学生。
返回结果表按照 student_id 排序。
返回结果格式如下。

AC:
SELECT student_id,
student_name
FROM Student
WHERE student_id NOT IN (SELECT DISTINCT student_id
FROM Exam AS E1
LEFT JOIN
(SELECT exam_id,
MIN(score) AS min_score,
MAX(score) AS max_score
FROM Exam
GROUP BY exam_id) AS E2
ON E2.exam_id = E1.exam_id
WHERE E1.score = E2.min_score
OR E1.score = E2.max_score)
AND student_id IN (SELECT DISTINCT student_id FROM Exam);
10.两人之间的通话次数


AC:
select person1,
person2,
COUNT(duration) as call_count,
SUM(duration) as total_duration
from (
select from_id as person1,
to_id as person2,
duration
from Calls where from_id < to_id -- 找出from_id < to_id所以信息
union all
select to_id as person1,
from_id as person2,
duration
from Calls where to_id < from_id -- 找出from_id > to_id所以信息
) t -- 用union all连接两个表即可
group by person1, person2;11.最后一个能进入巴士的人
表: Queue
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| person_id | int |
| person_name | varchar |
| weight | int |
| turn | int |
+-------------+---------+
person_id 是这个表具有唯一值的列。
该表展示了所有候车乘客的信息。
表中 person_id 和 turn 列将包含从 1 到 n 的所有数字,其中 n 是表中的行数。
turn 决定了候车乘客上巴士的顺序,其中 turn=1 表示第一个上巴士,turn=n 表示最后一个上巴士。
weight 表示候车乘客的体重,以千克为单位。
有一队乘客在等着上巴士。然而,巴士有1000 千克 的重量限制,所以其中一部分乘客可能无法上巴士。
编写解决方案找出 最后一个 上巴士且不超过重量限制的乘客,并报告 person_name 。题目测试用例确保顺位第一的人可以上巴士且不会超重。
返回结果格式如下所示。
示例 1:
输入:
Queue 表
+-----------+-------------+--------+------+
| person_id | person_name | weight | turn |
+-----------+-------------+--------+------+
| 5 | Alice | 250 | 1 |
| 4 | Bob | 175 | 5 |
| 3 | Alex | 350 | 2 |
| 6 | John Cena | 400 | 3 |
| 1 | Winston | 500 | 6 |
| 2 | Marie | 200 | 4 |
+-----------+-------------+--------+------+
输出:
+-------------+
| person_name |
+-------------+
| John Cena |
+-------------+
解释:
为了简化,Queue 表按 turn 列由小到大排序。
+------+----+-----------+--------+--------------+
| Turn | ID | Name | Weight | Total Weight |
+------+----+-----------+--------+--------------+
| 1 | 5 | Alice | 250 | 250 |
| 2 | 3 | Alex | 350 | 600 |
| 3 | 6 | John Cena | 400 | 1000 | (最后一个上巴士)
| 4 | 2 | Marie | 200 | 1200 | (无法上巴士)
| 5 | 4 | Bob | 175 | ___ |
| 6 | 1 | Winston | 500 | ___ |
+------+----+-----------+--------+--------------+AC:
SELECT t1.person_name
FROM Queue t1
WHERE (
SELECT SUM(t2.Weight)
FROM Queue t2
WHERE t2.Turn <= t1.Turn
) <= 1000
ORDER BY t1.Turn DESC
LIMIT 1
12.树节点
表:Tree
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| p_id | int |
+-------------+------+
id 是该表中具有唯一值的列。
该表的每行包含树中节点的 id 及其父节点的 id 信息。
给定的结构总是一个有效的树。
树中的每个节点可以是以下三种类型之一:
-
**"Leaf"**:节点是叶子节点。
-
**"Root"**:节点是树的根节点。
-
**"lnner"**:节点既不是叶子节点也不是根节点。
编写一个解决方案来报告树中每个节点的类型。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
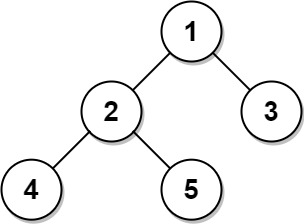
输入:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
+----+------+
输出:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
| 2 | Inner |
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
+----+-------+
解释:
节点 1 是根节点,因为它的父节点为空,并且它有子节点 2 和 3。
节点 2 是一个内部节点,因为它有父节点 1 和子节点 4 和 5。
节点 3、4 和 5 是叶子节点,因为它们有父节点而没有子节点。AC:
SELECT id, 'Root' AS Type
FROM tree
WHERE p_id IS NULL
UNION
SELECT id, 'Leaf' AS Type
FROM tree
WHERE id NOT IN (SELECT DISTINCT p_id
FROM tree
WHERE p_id IS NOT NULL)
AND p_id IS NOT NULL
UNION
SELECT id, 'Inner' AS Type
FROM tree
WHERE
id IN (SELECT DISTINCT p_id
FROM tree
WHERE p_id IS NOT NULL)
AND p_id IS NOT NULL13.筛选昵称规则和试卷规则的作答记录
描述
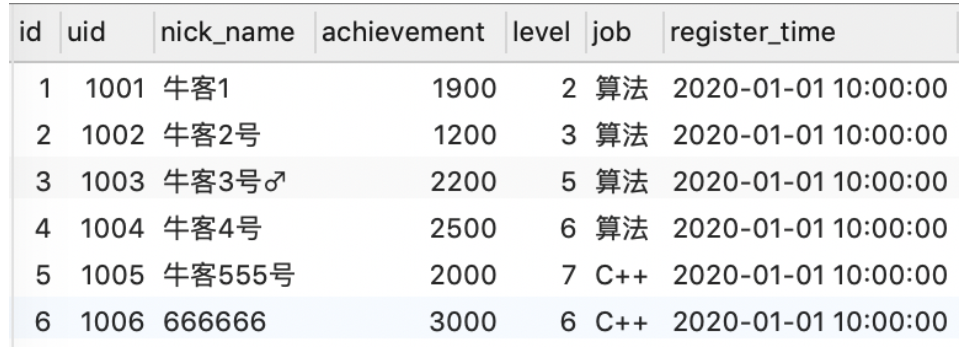
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):
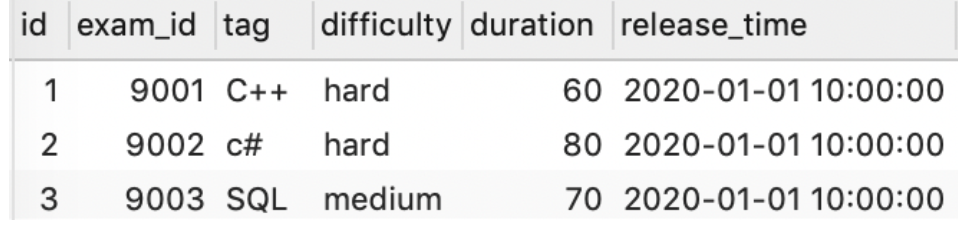
试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):
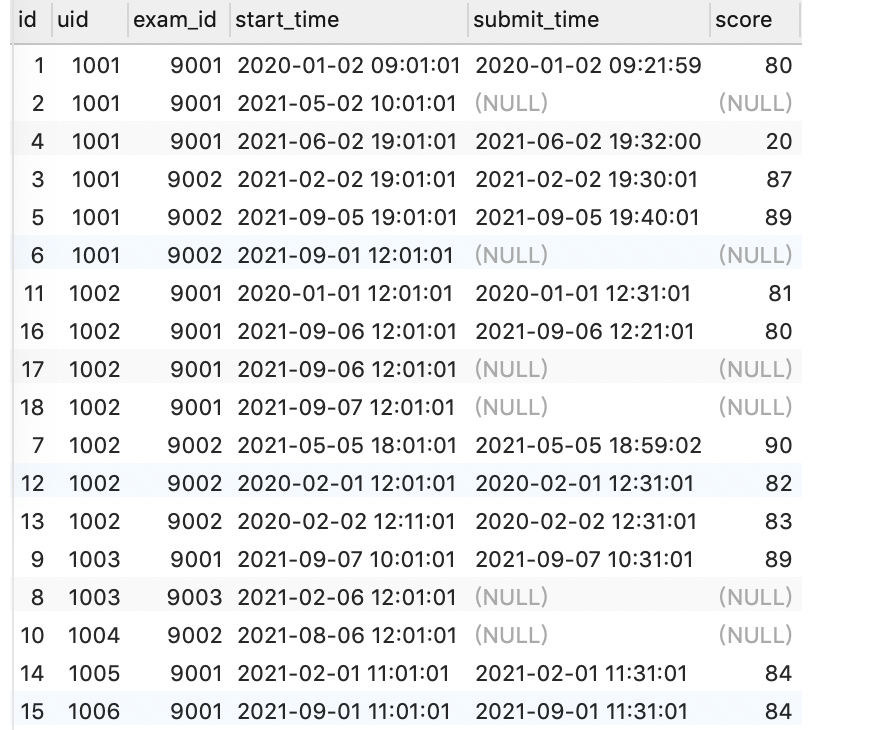
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
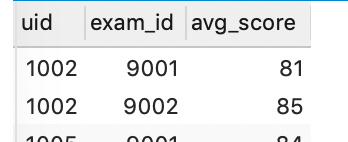
找到昵称以"牛客"+纯数字+"号"或者纯数字组成的用户对于字母c开头的试卷类别(如C,C++,c#等)的已完成的试卷ID和平均得分(四舍五入),按用户ID、平均分升序排序。由(部分)示例数据结果输出如下:
AC:
select user_info.uid,exam_record.exam_id,
round(avg(score),0) as avg_score
from user_info
left join exam_record on exam_record.uid=user_info.uid
left join examination_info on examination_info.exam_id=exam_record.exam_id
where (tag like 'c%' or tag like 'C%')
and (nick_name rlike '^牛客[0-9]+号$' or nick_name rlike '^[0-9]+$')
and submit_time is not null
group by user_info.uid,exam_record.exam_id
order by user_info.uid,avg_score